RTX 5090 D和RTX 5080是同期开售的,不外它们的解禁时辰不那么一样。前段时辰咱们依然评测了RTX 5090 D澳门六合彩,今天咱们就来看一看次旗舰GeForce RTX 5080。尽头值得一提的是,此次RTX 5080是有Founders Edition的——NVIDIA自家的瞎想向来自成一片,本次RTX 50系更因其稳当SFF-Ready(适用于SFF小尺寸)法度的超薄瞎想而惹人注目。讲真,我致使合计不少艳羡者会胜仗因为Founders Edition的这个尺寸跳过性能展示部分胜仗下单了,不外这倒不是不写评测到街上放烟花的意义。因此,接下来就让咱们充满敬爱心,好好地看一下这张显卡内与外。

规格表




硬件架构默契
这里的架构默契主若是涵盖RTX 50系GPU的硬件方面,如果思要阅读包括神经集结渲染、RTX Mega Geometry等时刻的详备架构默契,请阅读RTX 5090 D的评测:《iGame GeForce RTX 5090 D Advanced评测:散热稳压大中枢,DLSS 4旷古绝伦》
Blackwell GB203中枢:RTX 5080出场即满血
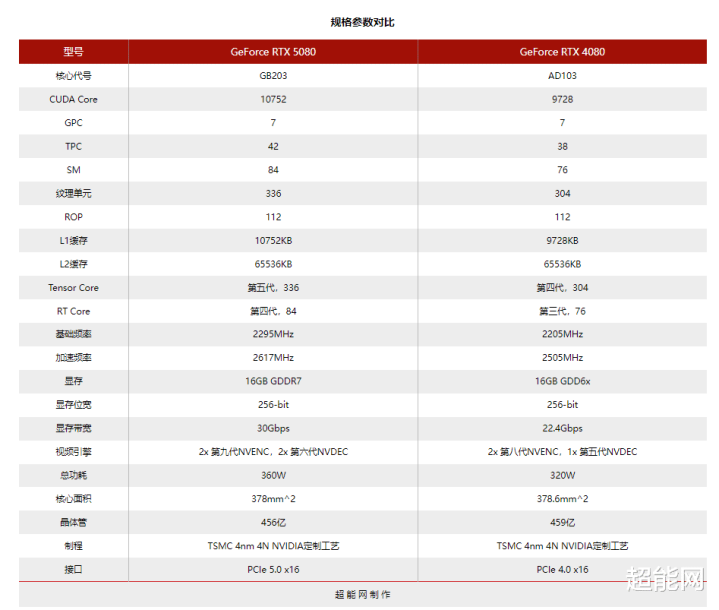
和上一代序列一样,轮到RTX 5080的即是GB203中枢了。好意思满的GB203中枢共领有456亿晶体管。前边在RTX 5090 D评测依然说过,在Blackwell这一代上,如故GPC-TPC-SM层级瞎想。GB203共领有7 GPC,42 TPC,84 SM,10752个CUDA中枢——我思这里你能看出一丝离别:何如TPC是42个?是的,天然刻下咱们还莫得好意思满的中枢架构图,但是用浅薄的乘除法就知说念,GB203上每组GPC如故和前代一样包含6组TPC。不外有一个好音问是,此次RTX 5080出场即满血,这点跟它的前辈不一样。
在GPC段,可见它包含的TPC从Ada Lovelace的6组扩张到了8组。不外布局上如故一样的,一个孤独的光栅引擎,两个ROP分区(每个包含8个ROP单位),而每组TPC包含两组SM。
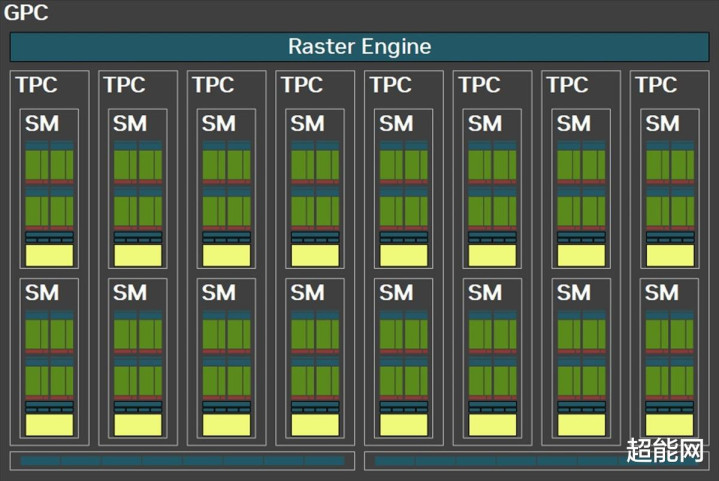
到达SM段,这里的变化是比较大的。领先,刻下通盘的32个CUDA中枢都能施行FP32/INT32运算了,因此INT32的算力可以说是加多了一倍。不外在一个时钟周期里面,中枢只可二选一运算,要不FP32,要不INT32。NVIDIA示意这种瞎想是为神经集结着色器优化的。Tensor Core和RT Core天然也有升级,不外让咱们先说完新的显存。
GDDR7显存:带宽高能耗低
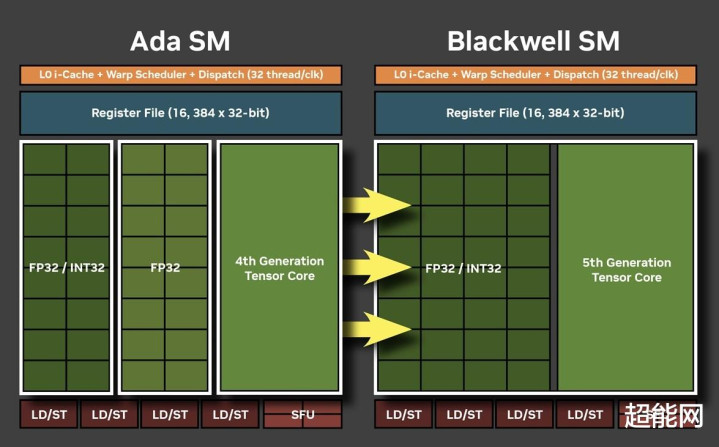
RTX 40系上的GDDR6X是NVIDIA和好意思光配合打造的,因此你就只可在NVIDIA的产物上看到GDDR6X,而且部件号无一例外全是D8BZC,别无二家了属于是。在RTX 50系列这一代上,NVIDIA是和法度制定者JEDEC固态时刻协会配合,推出了全新的GDDR7显存。
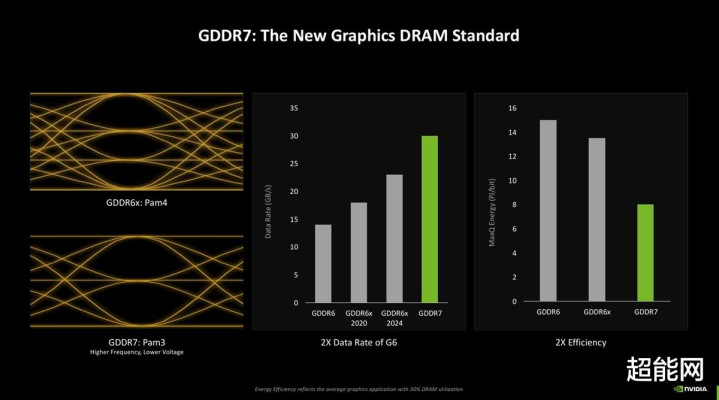
NVIDIA示意,GDDR7显存遴选了PAM3调制,这能让它在信噪譬如面有所栽植,通说念的密度也加多了。性能方面,GDDR7能带来更高的带宽,同期比GDDR6X/GDDR6要节能得多。
第5代Tensor Core:新增FP4撑抓
第5代Tensor Core秉承了上一代架构的特质,并新增了FP4、FP6的撑抓,还把FP8 Transformer Engine更新到了第二代。
FP4撑抓显然是民众比较蔼然的。NVIDIA对此的评释是,跟着生成式AI模子材干的栽植,旧例的FP16模子对硬件尽头是显存的条件有增无已,在单张显卡上初始这些模子会变得十分贫瘠。而FP4模子需要的显存更小,在TensorRT模子优化器(Model Optimizer)的撑抓下还能作念到简直莫得质料耗费,对于通盘这个词RTX 50系列来说是很友好的,毕竟不是每张卡都有RTX 5090 D那么大显存。
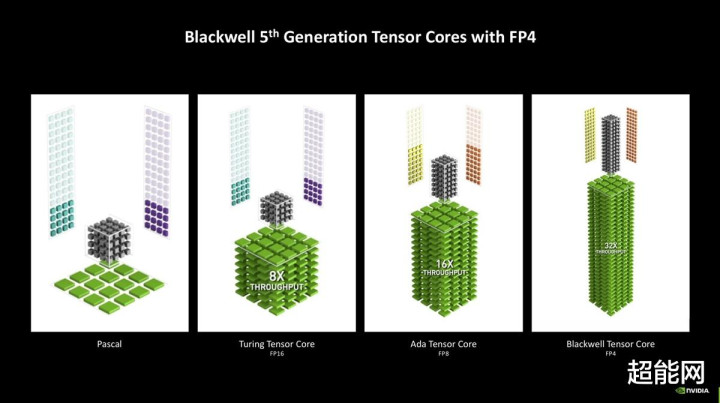
为什么要强调单张卡也可以初始呢?这其实跟游戏也联系系,在咱们之前的报说念里说过,NVIDIA一直在捣饱读NVIDIA ACE这个AI NPC时刻,再加上别的基于AI的游戏时刻也要用到Tensor Core,因此提高模子的初始恶果很有必要。
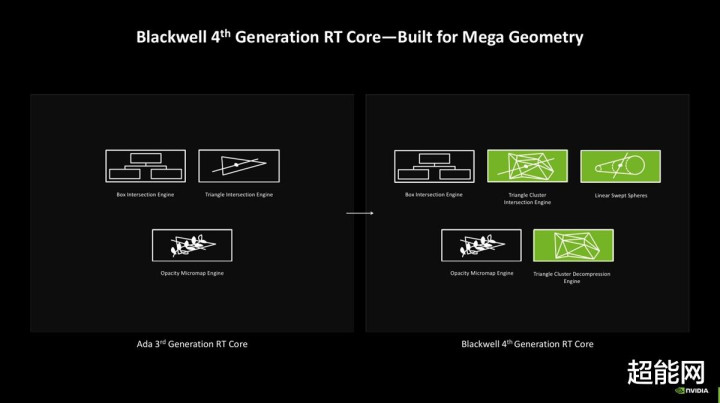
第4代RT Core:为RTX Mega Geometry准备
在第4代RT Core上头咱们仍然能见到一些熟练的组件,比如Box Intersection Engine和Opacity Micromap Engine这两个加快引擎,它们隔离针对BVH树遍历和透明物体进行加快。而新增的组件包括Triangle Cluster Intersection Engine和Triangle Cluster Compression Engine,以及Linear Swept Spheres。
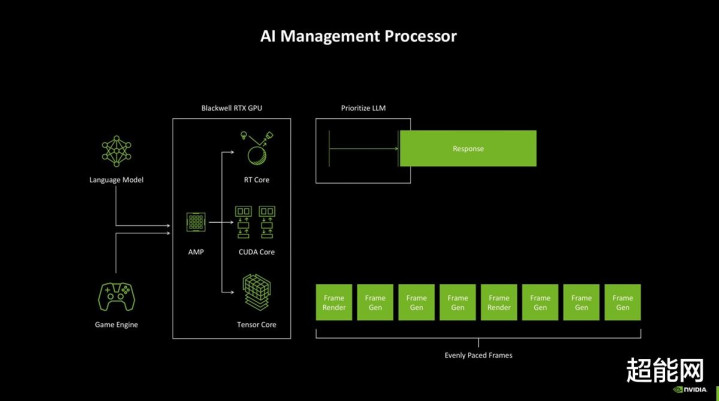
AI-Management Processor和着色器施行重排序2.0
AI-Management Process(AMP)在架构图上和GigaThread Engine并排,可见它亦然个调养器。AMP的本色是一个位于管线前端的RISC-V处理器,它撑抓Windows硬件加快GPU决策,能够更解放地不断GPU。
AMP不异跟AI游戏联系。这里举个例子,腹地初始LLM的话,它们初次反应的时辰一般是比较慢的,这放在常识库聊天机器东说念主里还好,民众可能都民风了,但是对于游戏来说,这即是另一种情景了:试思一下你绽开游戏加载归档,刚思找npc接个任务,猖狂npc憋了半天才冒出一句“你好”,这确乎很破损游戏体验。
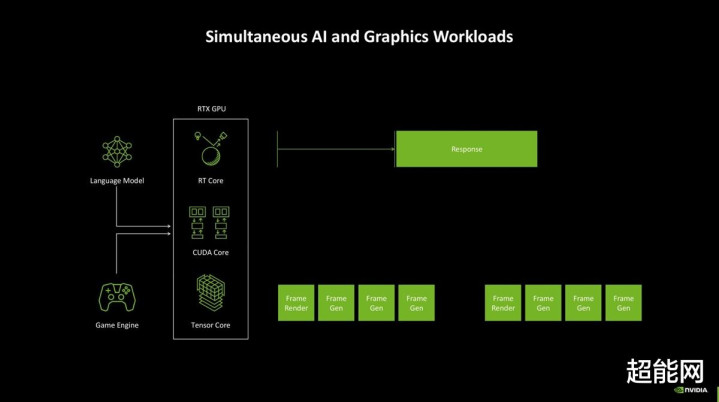
同期运作的话,LLM的反适时辰变慢,游戏帧率也会受影响
而在AMP的撑抓下,CUDA、RT Core和Tensor Core三大部分可以调和使命。如图所示,AMP提高了LLM的优先级,令其更早启动,作念到在游戏中实时反应,并同期让游戏引擎、DLSS 4保抓牢固的帧率输出。
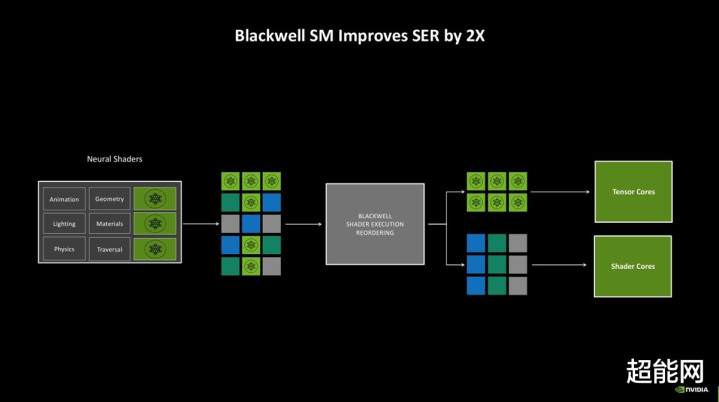
在Ada Lovelace上的着色器施行重排序(SER)主若是针对明后跟踪而瞎想的。通过对明后跟踪任务的动态重排序,该功能可充分提高硬件使用率。而Blackwell上的SER 2.0还可以将神经集结的负载胜仗发送至Tensor Core处理,加快神经集结渲染。NVIDIA示意,Blackwell上的SER重排序逻辑恶果达到了前代的2倍,假造支拨之余还能提高精确度。
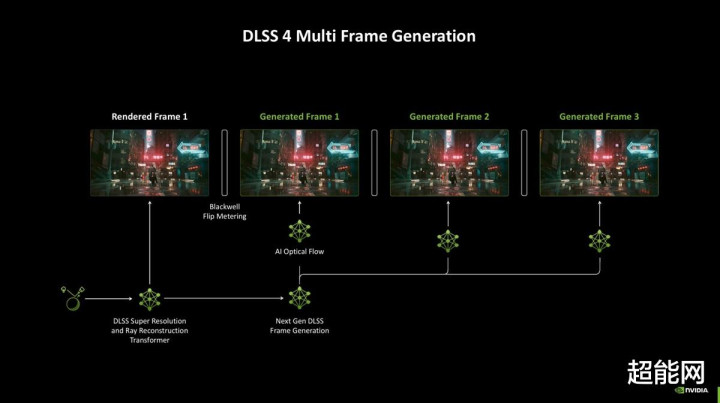
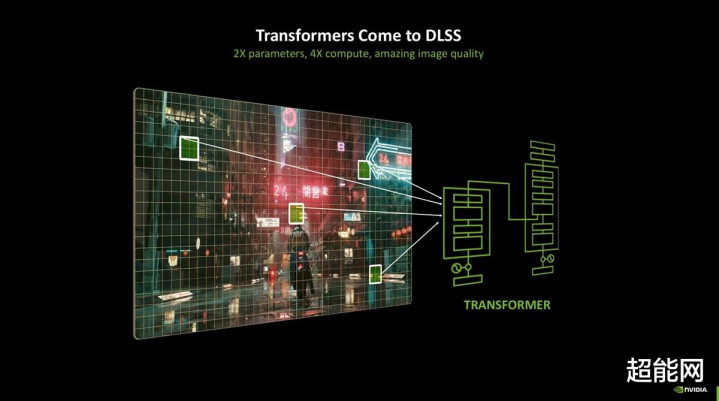
DLSS 4:多帧生成还有模子升级
咱们终于说到DLSS 4了!说真话DLSS 3引入的帧生见着力依然挺让我惬意的了,而DLSS 4则是更进一步,带来了多帧生见着力。这个我思应该无谓过多评释,即是渲染1帧最高生成3帧。另外,我在最近的Editor's Day上问过NVIDIA对于多帧生成极限的问题,他们示意这AI模子是可以生成更多帧的,但是3帧是一个比较合理的值,因为DLSS 4是多个AI模子沿路使命的,是以工程师在瞎想时不只单要酌量帧生成的问题,再说了,生成3帧带来的栽植依然充足强力了。
接下来咱们就一一拆分DLSS 4的各项组件,望望它们有什么更新,又是若何协同使命。
领先是民众都关注的帧生成,NVIDIA Blackwell的帧生成模子比上一代快了40%,同期显存占用假造30%。同期,用于提供光流场信息的不再是RTX 40系列上的光流加快器,而是一个更高效的AI模子。
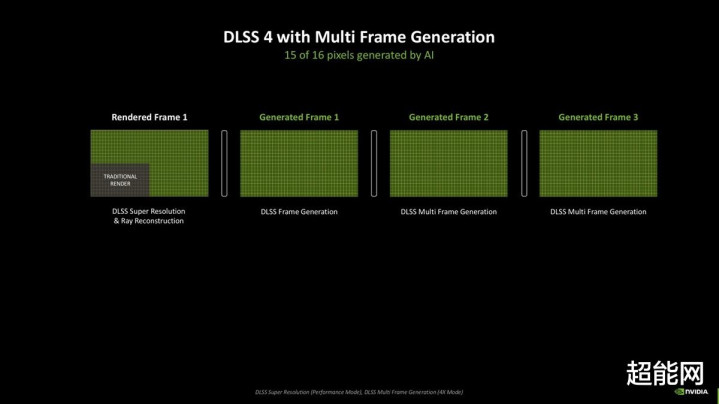
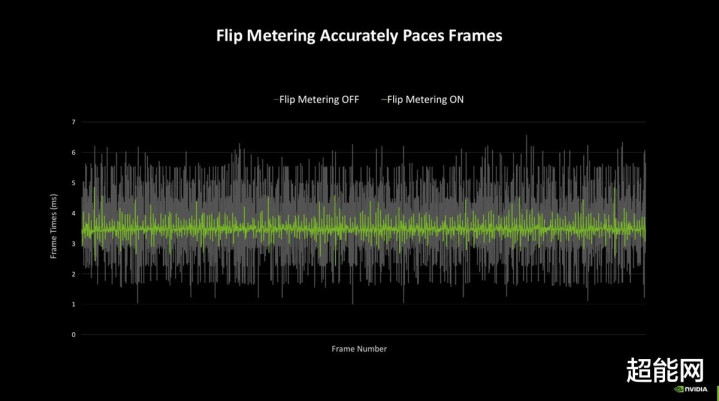
不外如斯一来新的问题就产生了:在Ada Lovelace上,DLSS 3是渲染一帧生成新的一帧,即是帧1,1.1,2,2.1...这种,把控每帧的输出法举例故比较容易的,因为生成的帧1.1总在渲染的帧1背面,如果来不足输出帧1.1,那就把它丢掉,胜仗输出帧2就好。而RTX 40系上的DLSS 4是1,1.1,1.2,1.3,2,2.1,2.2,2.3,3...,中间整整隔了生成的3帧,何如不让输出法例乱套即是新的问题。为此,Blackwell引入了硬件级Flip Metering(这个名词确乎很难描写,直译是翻转测量),这个组件将帧平滑逻辑从CPU转化到GPU的闪现引擎上,让GPU更精确地掌控闪现每一帧的节拍,假造帧与帧之间的时辰波动。开启后NVIDIA示意,Blackwell的闪现引擎取得了两倍像素处理材干,这样就可以撑抓高分辨率、高刷新率下的Flip Metering。
由于DLSS 4多帧生成需要用到第5代Tensor Core的苍劲算力去计较光流场和生成多帧,因此这个功能刻下是Blackwell独占的。
然后比较让东说念主惊喜的是,超分辨率、明后重建、DLAA也取得了更新,它们的模子从CNN换成了Transformer,一个给与自预防力机制的神经集结,适用于从RTX 20-50的全线RTX GPU。不外我思在这里说明CNN和Transformer两个神经集结有什么区别全都会喧宾夺主,光是编码器妥协码器就够喝一壶的了。因此只需要知说念新的模子能够提高画面的牢固性,栽植光照细节,赐与动态物体更多细节即可。大伙可以不才面的DLSS 4测试中十分直不雅地看到这两个模子的画面离别。
NVENC和NVDEC新增Y′CbCr 4:2:2撑抓
刻下好多录像机都撑抓录制4:2:2形式的视频,这是有原因的:4:2:2比较起4:4:4更从简储存空间,但是比起4:2:0能保存更多的情怀,这样一来就给后期调色留住了充足的空间。Blackwell此次新增了4:2:2的编解码撑抓,可提高创作家的恶果,比如说导出时辰减少,更流通的多路回放等。NVIDIA示意,第6代NVDEC可同步解码和播放多达8个4K60 4:2:2视频流。

而第9代NVENC则栽植了HEVC和AV1的编码质料,为4:2:2 H.264和HVEC编码提供了撑抓。另外,还有一个全新的AV1 Ultra High Quality(UHQ)模式,它可以用更多的时辰去取得格外5%的质料栽植。NVIDIA还示意,这个模式在RTX 40系列上也可用,不外Blackwell的质料是更好的。
外不雅瞎想和里面
GeForce RTX 5080 Founders Edition给与了新的包装瞎想,与上一代的Founders Edition有所不同,从材质、结构和配色来看都十分绿色环保。让我思起了一些手机的包装盒。不得不说拆箱的时候挺有典礼感的,先拔掉凹凸两块固定板,就能把上盖拿起来,RTX 5080 FE就静静地躺在其中。
 澳门六合彩
澳门六合彩








RTX 5080 FE保抓了公版显卡一向优秀的外不雅瞎想,一看这象征性的无穷象征外框就知说念是NVIDIA同胞的手笔。金属材质不但面子,而且触感十分棒。全新的散热不断步调让新一代FE显卡的体态变得苗条,正面两侧是定制的大直径电扇,背面两侧布满了大面积的格栅,以团结标的垂直陈列。此次NVIDIA给与了从GTX 10系列到RTX 40系列历代公版显卡在散热瞎想上的教学,在RTX 5080 FE显卡上引入了名为“Double Flow Through”的新款散热器瞎想,带来了更为高效的散热恶果。









RTX 5080 FE显卡保抓了双槽厚度,长度和高度隔离为304mm和137mm,完全满足SFF-Ready法度的条件。如果与RTX 4080这些民众伙放在沿路对比,那么体积上的差距就很昭彰了,尽头在厚度上,RTX 5080 FE薄了许多。另外还能看到,RTX 5080 FE的12V-2x6供电接口给与了新的歪斜瞎想,视频接口也180°调转了,对于插线来说更为友好。同期因为散热瞎想的更正,I/O挡板莫得了启齿,尾部一体感很强。







和前几代一样,RTX 5080 FE的灯光除了在侧边的GeForce RTX接口外,还藏在了框架中间的X形处,启动时就会亮起白光,配合着整都的格栅和平滑的外壳,可以说是是科幻又巧妙。由于全新的散热瞎想,举座瘦身的RTX 5080 FE不需要显卡支架,也没在尾部留住螺丝孔,装在机箱里面很干净,莫得别的东西来打扰它。









至于拆解的话,从性能影响的角度开拔,就算我个东说念主十分但愿能够一窥其里面分外小巧的三片PCB瞎想,也不太好把它逐件理解——毕竟难点在于背面的恢归附状,光有外不雅可不可,性能也得到位。不外还好,NVIDIA专诚出了一期聊Founders Edition散热瞎想的视频,从里面咱们能知说念这种平地风雷的结构是何如出身的(底下的截图援用自该视频【统一】)。而咱们背面向NVIDIA证明了,因为总功耗更低,是以RTX 5080 Founders Edition给与的是旧例均热板瞎想,导热材料是硅脂。不外热管数目倒莫得削减,亦然双方各5根。
纳税人错误确认发票用途为用于出口退税、代办退税的,可以向主管税务机关申请更正。如果纳税人尚未申报出口退税,经主管税务机关确认后,可将发票信息回退至电子发票服务平台,纳税人可以重新确认发票用途;如果纳税人已申报办理出口退税,可向主管税务机关申请开具出口货物转内销证明。

测试平台
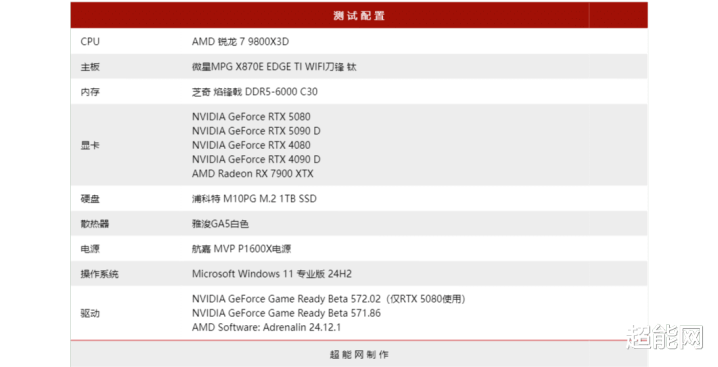
本次的测试平台和RTX 5090 D一样,以AMD 锐龙7 9800X3D和X870E主板为中枢,可确保显卡性能的全力阐明。说真话也莫得换平台的必要。至于对比显卡的话,此次就丰富多彩好多了,不仅有RTX 4080,还有AMD Radeon RX 7900 XTX,致使还有RTX 4090 D——它刚刚才在RTX 5090 D的测试里面亮相了,刻下还要不绝上班,就跟我一样。
而测试驱动则是Beta版的Game Ready驱动,不外因为测试的先后法例问题,RTX 5080用的是572.02,其他的RTX显卡用的是571.86。系统则是最新版的Windows 11 24H2。在游戏记载数据这块,如果游戏自带Benchmark的话,咱们会优先遴选Benchmark提供的成绩;如果游戏需要手动测试,咱们会用NVIDIA Frameview去记载成绩。由于这张显卡的高端定位,游戏的成立都是预设的最高了,明后跟踪亦然,惟一游戏撑抓咱们都会胜仗开全景明后跟踪/旅途跟踪。
基准测试
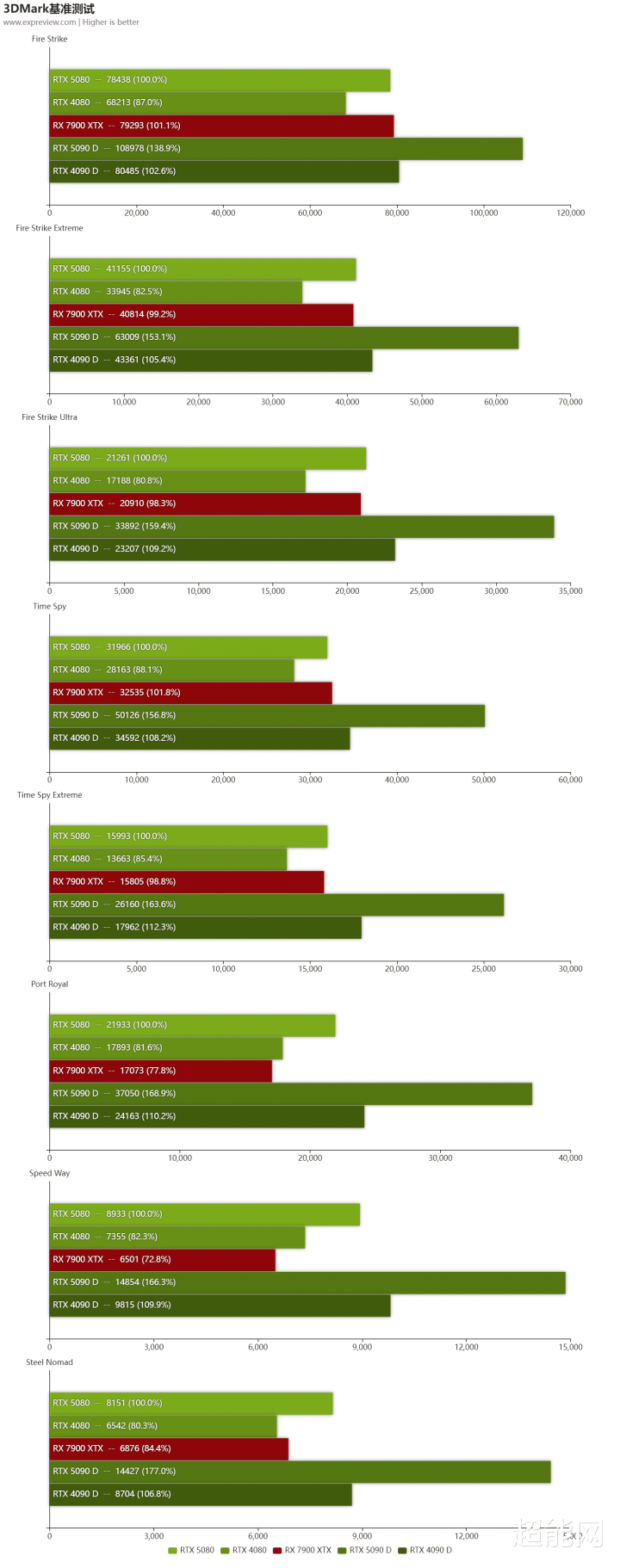
来望望3DMark的数据先吧。RTX 5080在各方面都比RTX 4080好好多,算下来增幅有20%,酌量到AD103和GB203在领域上的相似性,你可以大约相识成这即是Blackwell的代际栽植幅度。RTX 5080在4K分辨率的测试里面跟RTX 4090 D有着约10%的差距。和RX 7900 XTX对比的话,RTX 5080和它在传统光栅化性能上大约是抓平的,不外光追性能即是另一趟事了,绿色小队在明后跟踪这块一直是BIG BOSS。
其实可以看到中枢领域和基准测试的数据是很好对应的,RTX 5080的领域差未几是RTX 5090 D的50%,那么在传统和光追测试里面的分数也这样,RTX 5080的分数条比RTX 5090 D的一半多一丝。天然,咱们也就在3DMark这里展示一下GB202和GB203的差距,游戏数据就不放了,毕竟这两张卡在建立和售价上完全不是一个级别的。
游戏测试
DLSS 4性能测试
在前些天的RTX 5090 D评测(还有上头的架构默契)里面,咱们依然先容了DLSS 4的特质,因此在这里咱们就尽量欠妥复读机了。提及来,《赛博一又克2077》前几天稳健推送了DLSS 4更新,如果你依然在用RTX显卡的话,刻下是可以切躯壳验DLSS 4里面的全新Transformer模子的——涵盖超分辨率和明后重建。天然,多帧生成仍然是RTX 50系显卡的专属功能。
此次咱们一共测试了三款游戏,包括游戏内集成DLSS 4的《赛博一又克2077》和《星球大战》,以及通过NVIDIA App优设功能竣事DLSS 4的《漫威争锋》。天然咱们刻下测试的DLSS 4游戏数目是有限的,但当你们收到RTX 50系显卡的时候,应该就会有好多游戏取得原生DLSS 4或通过NVIDIA App的DLSS优设撑抓了,NVIDIA示意首日撑抓的游戏和行使数目会多达75款。
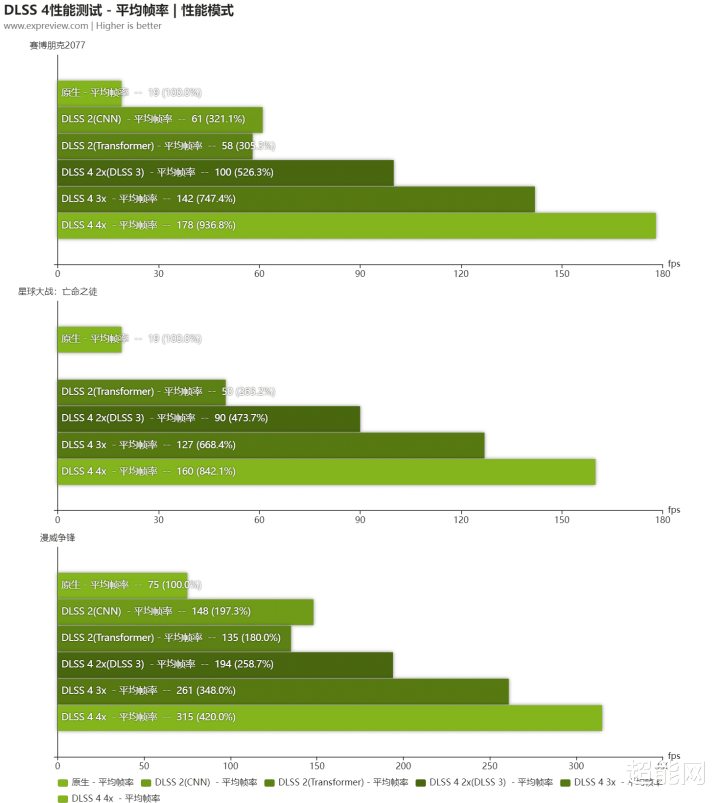
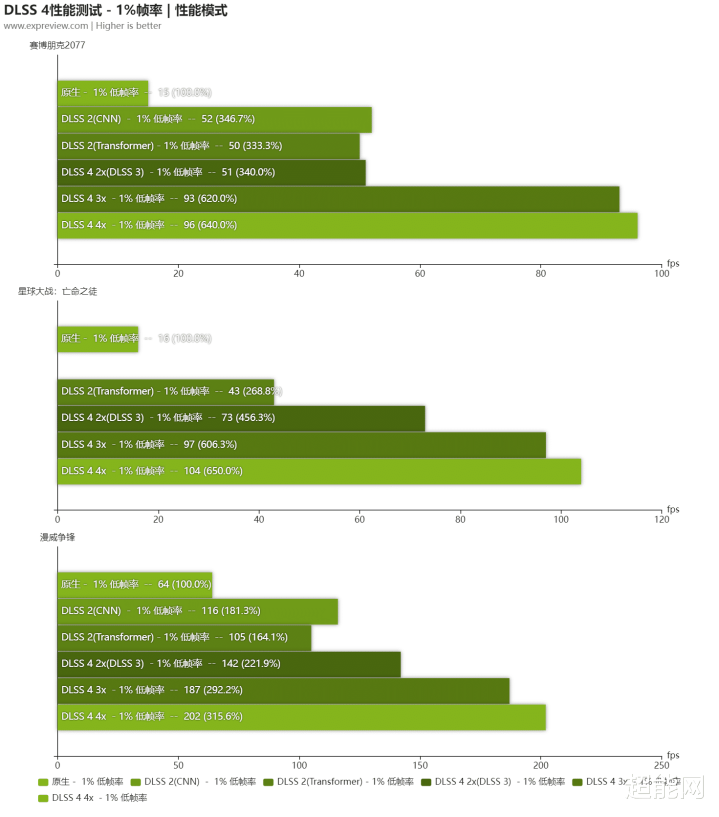
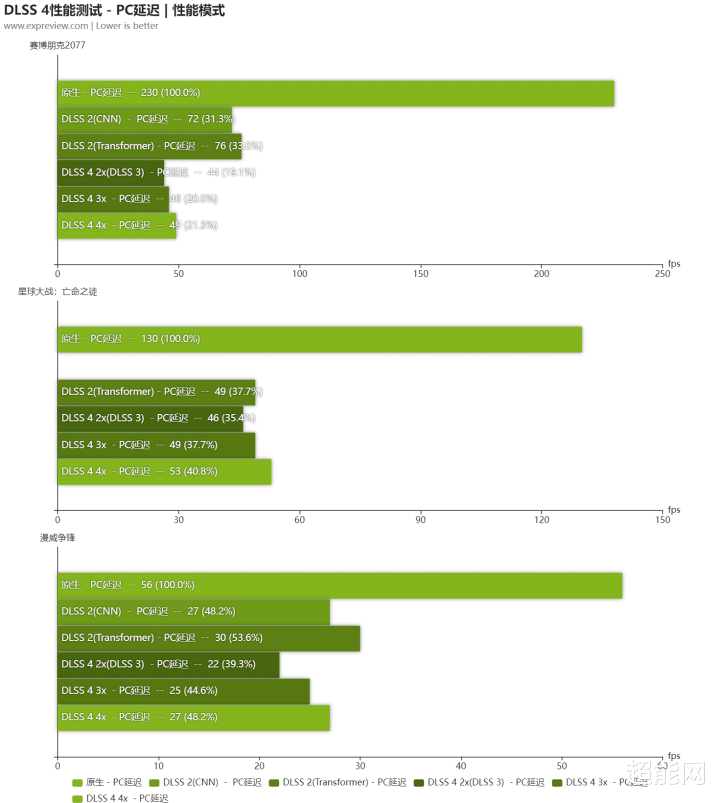
可以看到在全景明后跟踪开启且DLSS 4全开的情况下,《赛博一又克2077》和《星球大战:漏网之鱼》从不可玩现象胜仗冲到了三位数帧率。尽头是《星球大战:漏网之鱼》,在DLSS 3里面平均帧率只达到90fps,在多帧生成的撑抓下,就能冲上120乃至160fps的岑岭!而蔓延的话就更无谓驰念了,确凿不可的话你也可以开3x多帧生成,归正此时帧率依然很够了。
至于Transformer和CNN新旧模子的对比上头,咱们就胜仗援用RTX 5090 D测试时的截图了——因为新模子是从RTX 20-50系都能用的,是以你就算拿一张RTX 3080,用和咱们不异的成立也能取得这种对比颇为昭彰的画面(天然,帧率细目没那么高)。底下通盘的对比截图均是在超分辨苟且能挡获取的,屏幕分辨率为4K,图形成立为明后跟踪超速。可以看到Transformer大幅度地改善了复杂场景里面的细节弘扬,比如门板夹层的金属部件、水面倒影和调料瓶瓶盖。


CNN模子CNN模子Transformer模子Transformer模子


CNN模子CNN模子Transformer模子Transformer模子


CNN模子CNN模子Transformer模子Transformer模子
4K分辨率
在旧例游戏测试这里,咱们保管了和RTX 5090 D不异的游戏气势。一共有7款光栅化游戏和6款光追游戏参加4K分辨率的测试,至于参加2K分辨率测试的游戏就少点,是光栅化游戏和光追游戏各4款。毕竟RTX 5080是一款定位4K分辨率的显卡,前者才是重心。
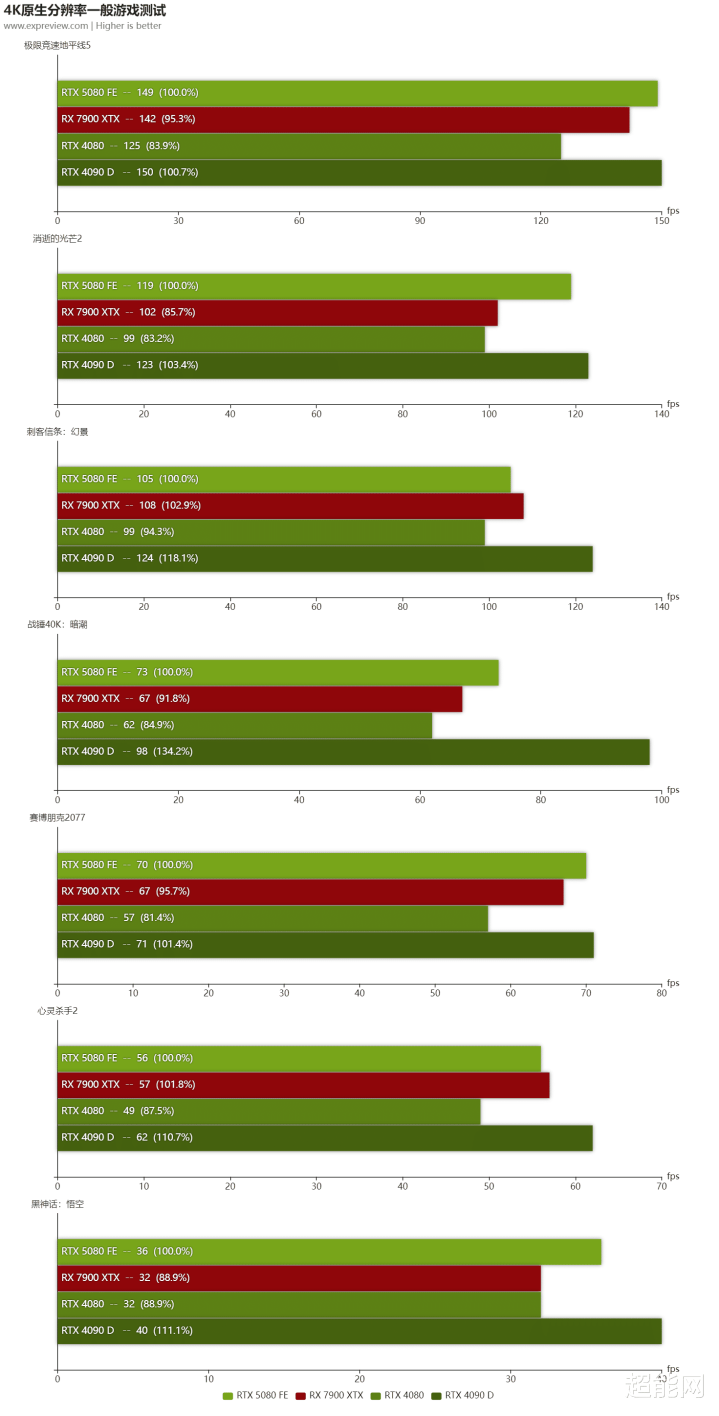
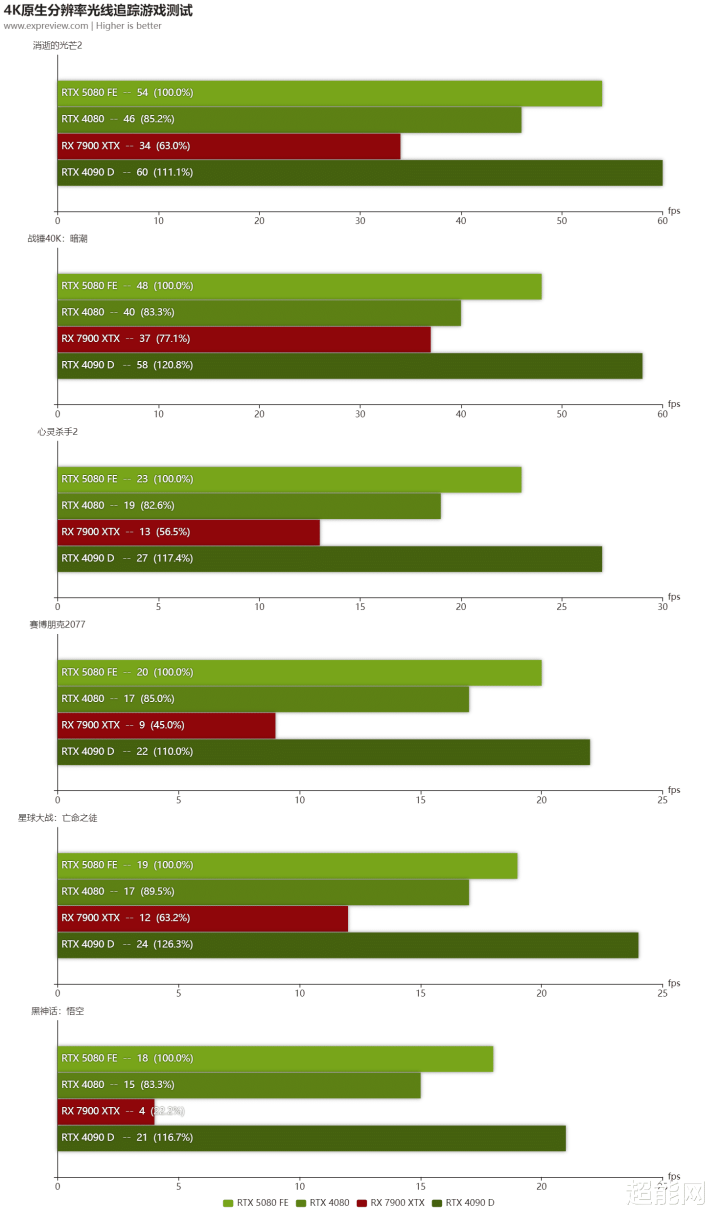
在原生4K分辨率游戏这块,RTX 5080在数个步地中都理所天然地超越了RTX 4080。在一些步地中,RTX 5080致使能迫临上一代旗舰RTX 4090 D,比如说在《极限竞速:地平线5》和《赛博一又克2077》这两款游戏中,这两张卡基本莫得区别。和RX 7900 XTX对比的话,RTX 5080也在大部分游戏里面超越了这张RX 7000系列最佳的显卡。
4K光追游戏这块,虽说咱们是有测试RX 7900 XTX的,但是它的成绩都太低了,一些全景光追游戏对它来说根底吃不用。因此咱们就只可不才面的2K分辨率里See you again了,刻下来专心看几张RTX显卡的对比。收获于第四代RT Core,以及更多的RT Core数目,RTX 5080比起RTX 4080有着越过15%的栽植!天然,RTX 4090 D的领域比RTX 5080大好多,是以它是力大砖飞,光追成绩比RTX 5080好也可以相识。不外别忘了,RTX 5080有多帧生成这一个机密刀兵,可以让光追游戏的帧率成倍高潮。
2K分辨率
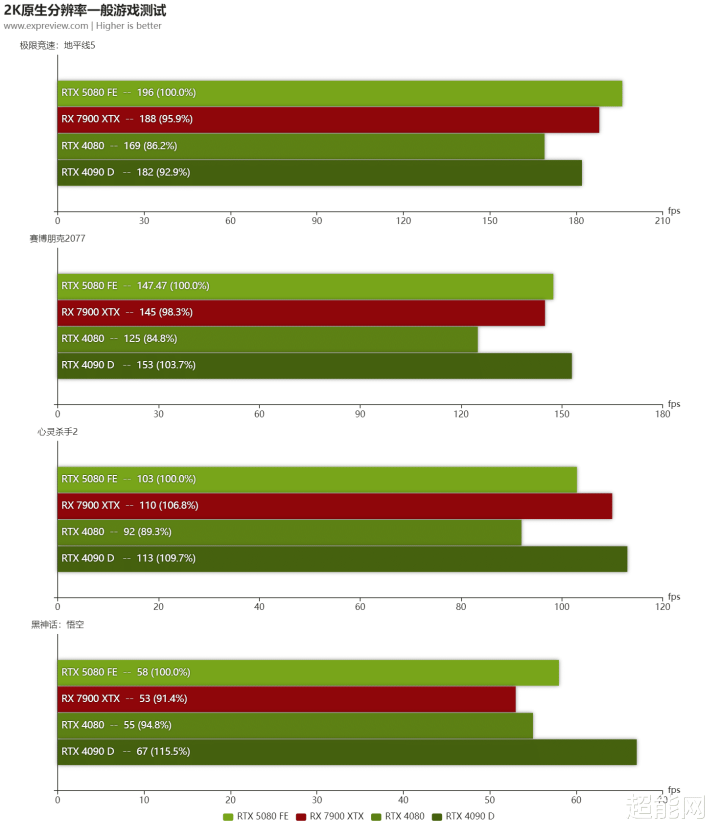
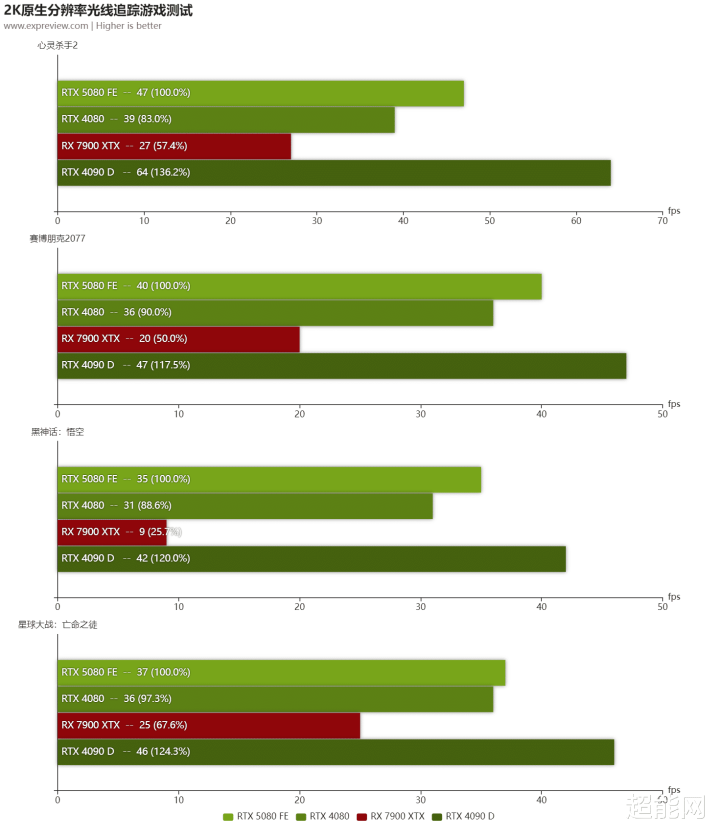
因为分辨率的假造,是以可以看见几张显卡的差距都有所减弱。不外比举例故如4K分辨率那般,RTX 5080的光栅化游戏性能在RTX 4090 D和RX 7900 XTX之间,越过RTX 4080不少。光追的话亦然如斯,RTX 5080在三张RTX显卡里面排行第二。
AI与坐褥力测试
AI生图与大言语模子
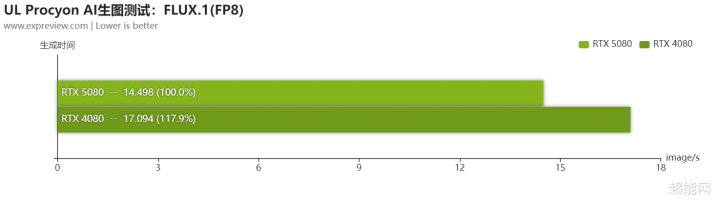
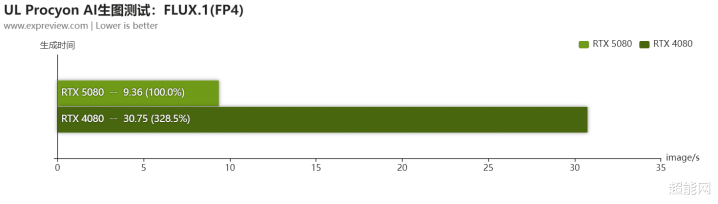
收获于Blackwell添加了对FP4的撑抓,在UL Procyon FLUX.1 AI生图测试里面,RTX 5080在FP4模式下仅用了10秒不到就生成了一张图,所用时辰连RTX 4080的1/3都不到。在FP8模式中,RTX 5080也比RTX 4080快,不外差距小一丝。
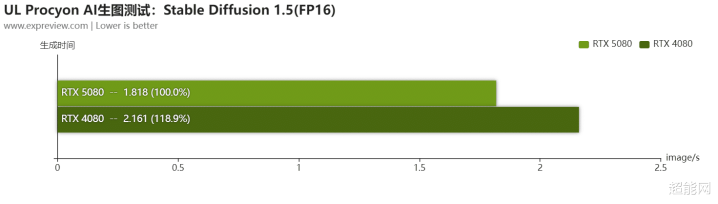
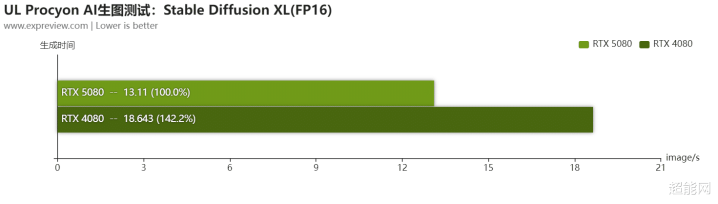
天然,旧例的UL Procyon Stable Diffusion FP16咱们也会测试。可见在这里RTX 5080仍然是要比RTX 4080快,在条件更高的Stable Diffusion XL中,RTX 5080生图时辰昭彰比RTX 4080裁减。酌量到咱们是用ONNX DirectML初始时测试的,若是Tensor RT日后稳健更新了对RTX 50系列的撑抓,大约这生成时辰还要短好多。
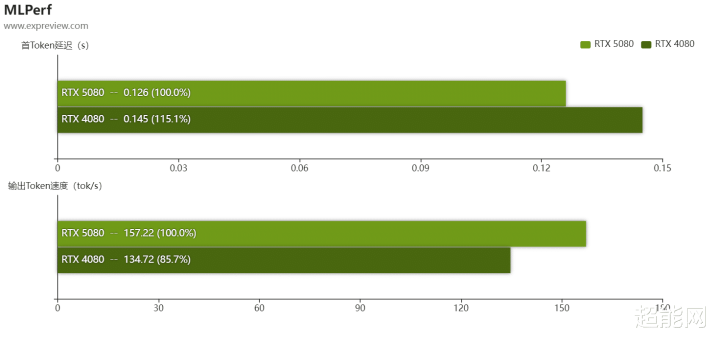
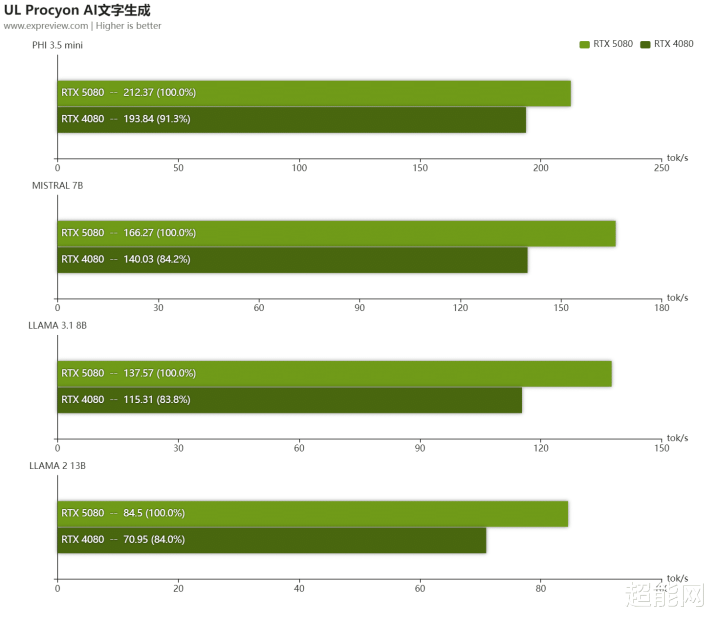
在LLM测试里面,RTX 5080在和输出Token速率这些要道野心上都比上一代快10-15%。
坐褥力创意软件
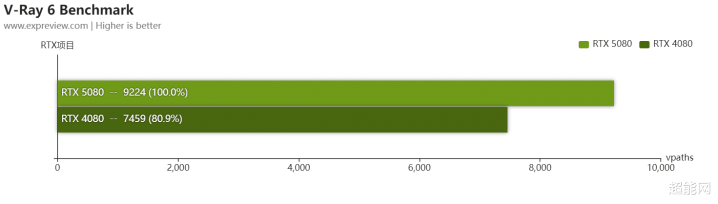
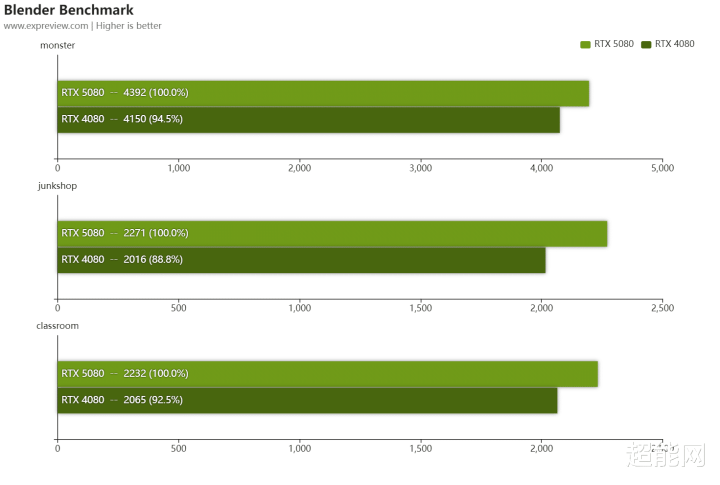
V-Ray和Blender都是跟3D创作联系的软件,在这里你可以看到RTX 5080是若何为创作提速的。在V-Ray 6 Benchmark中,RTX 5080要比RTX 4080快20%。
温度测试
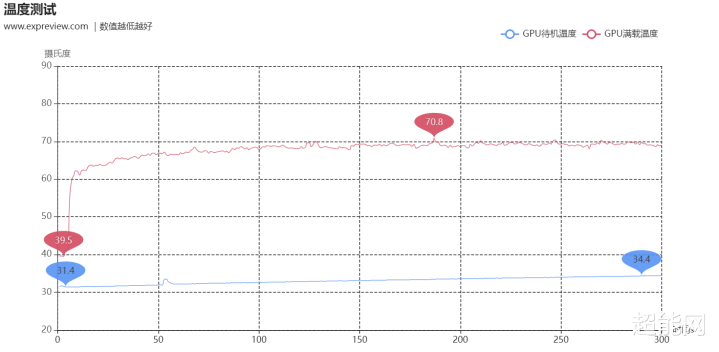
古道说这一代Founders Edition的尺寸确乎是一件颇为令东说念主颤抖的事,因此咱们对它的温度弘扬天然很感风趣。咱们是在开放平台测试RTX 5080的散热。测试分为待机和满载两个场景。待机场景是插足系统后待机5分钟,而满载场景则是3DMark Speed Way初始10分钟。咱们用GPU-Z的Log to file功能记载数据,环境温度是24.4摄氏度。历程测试,RTX 5080 FE的满载温度牢固在了68摄氏度凹凸。待机温度方面,则是由31.4冉冉高潮到34.4摄氏度,和其他带智能启停的显卡一样。酌量到这只是是一个2槽位显卡,这成绩挺可以的。
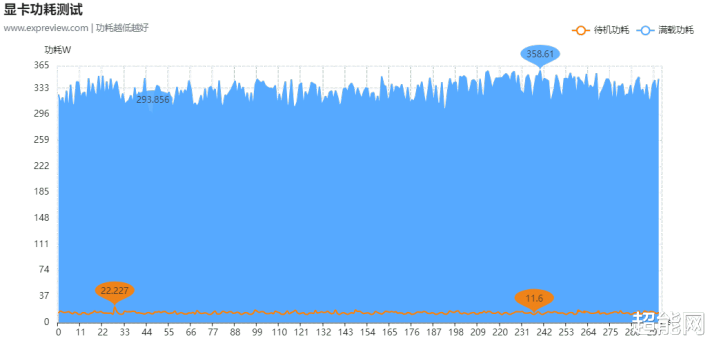
功耗测试
咱们通过手中的PCAT套件,隔离精确地测量显卡PCIe、外接电源接口的功耗,显卡满载功耗在3DMark Speed Way压力测试中取得,待机功耗则是在插足系统跋文录1分钟取平均值。测下来显卡的平均满载功耗达到了328W,峰值功耗的话,图里面是358W,不外记载数据里面最高有366W的记载,只是图里面刚好莫得遮掩辛勤。而待机功耗绝大部分时辰是在15W以下。总的来看是比RTX 4080/4080 SUPER这一代高了少量。电源推选方面,其实NVIDIA官方建议的850W是够用的。
杂音测试
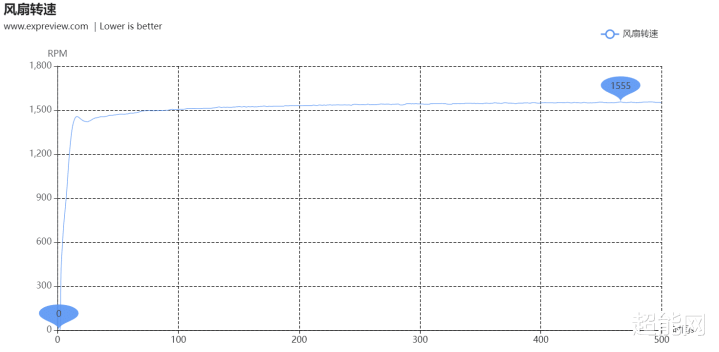
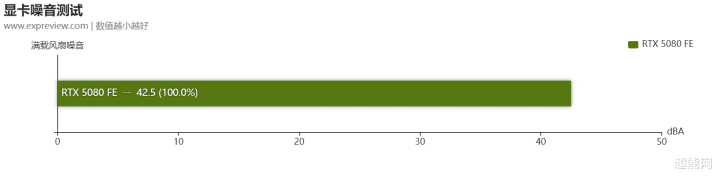
在GPU-Z的Log to File中咱们同期记载下了显卡转速情况。烤机时,RTX 5080电扇转速最高的时候在1550RPM凹凸。接着咱们把显卡放进了环境杂音小于10 dB(A)的消音实验室,把其电扇还原不异转速,然后在30CM的距离上测试其杂音水平,测得的数据是42.5BA。由于显卡在待机时电扇是停转的,是以就无谓测试了。

转头
可能是由于早些时辰的RTX 5090 D带来的冲击,加上数日来不分日夜的抓续测试,说真话RTX 5080给我带来的颤动其实莫得RTX 5090 D那么利害。可是必须要预防到的是,比较起领域暴涨的GB202,RTX 5080的GB203在组件的数目上和AD103更相似,在探讨架构代际栽植这个话题上,RTX 5080是更有代表价值的。从游戏测试里可以看到,RTX 5080在光栅化和光追游戏性能上都是稳步栽植,DLSS 4更是让其如虎添翼。个东说念主认为,如果你还在停留在RTX 30乃至20系旗舰的话,RTX 5080确乎可以让你一步高出,直抵4K。而对于刚买了RTX 4080和RTX 4080 SUPER的玩家而言,他们大约可以松语气,天然DLSS 4的确作念到了四倍增幅,但DLSS 3的双倍果然也不赖了。

不外,我战胜有这样一群玩家是最思要GeForce RTX 5080 Founders Edition的:他们同期追求体积的极限压缩和性能的旷古绝伦,如同《核舟记》的奇巧东说念主一般,要在小空间里描写大全国——对于这群ITX玩家而言,这一代Founders Edition全都是最佳的礼物。尽头酌量到这几代以来,高端显卡只大不小的趋势,NVIDIA能忽视SFF-Ready法度况兼身膂力行,作念出这样一张双槽猛兽,确乎称得上是历史鼎新。
显卡迷你天梯榜 (好意思满显卡天梯榜)

终末,如故说一说售价,GeForce RTX 5080 Founders Edition的价钱为8299元,相较RTX 40系发布时RTX 4090和RTX 4080时过于邻近的订价澳门六合彩,RTX 50系此次旗舰的凹凸搭配如故比较合理的。如果你只是拿来玩游戏,那RTX 5080确乎是很可以的一张高端显卡。